Die Suche nach einem bestimmten Tier auf unserer Datenbank könnte sich nach der Nadel im Heuhaufen erweisen. Die bisherige Tiersuche, welche auf der gesamten Datenbanktabelle suchte, war langsam und genügte nicht mehr den neusten Ansprüchen. Zudem wurden zu wenig Informationen zu den Resultaten angezeigt und das Suchen in den Resultaten war nicht benutzerfreundlich. Im Frühsommer 2018 wurde die Tiersuche überarbeitet.
Für uns und unsere Mandanten ist eine effiziente Suche aber sehr wichtig. Deshalb haben wir die Tiersuche in unserem System verbessert. Und genau so funktioniert diese Suche bei uns:
Auf der Datenbanktabelle ANIMAL der Qualitas sind rund 18.5 Millionen Tiere gespeichert (Datenstand per August 2018). Für die Qualitas und unsere Mandaten ist es entscheidend, schnell nach einzelnen Tiere suchen zu können. Für die Suche nach einem Tier auf der Datenbank, sind folgenden Tabellenfelder relevant:
- Technische ID: Primary Key der Tabelle ANIMAL, wird per Sequenz eindeutig vergeben
- TVD-Nummer: Nummer der Tierverkehrsdatenbank (Bsp. 120137939829)
- Kurzname: Name des Tieres
- Rasse: Rasse des Tieres

Wir suchen nicht die Nadel im Heuhaufen, sondern Kühe auf unserer Datenbank.

Eine Suche nach der technische ID eines Tieres oder der exakten TVD-Nummer (Nummer des Tieres auf der Tierverkehrsdatenbank) ist für die Datenbank eigentlich kein Problem. Das Ergebnis wird mithilfe des passenden Index innerhalb weniger Millisekunden gefunden.
Da sichergestellt ist, dass bei der Suche nach der technischen ID maximal ein Resultat gefunden wird, kann die Datenbank einen «UNIQUE_SCAN» ausführen. TVD-Nummern sind nur in Kombination mit dem Land und der Gattung eindeutig. Aus diesem Grund muss die Datenbank bei der Suche nach TVD-Nummer einen «RANGE SCAN» machen. Allerdings ist dieser etwas langsamer als der «UNIQUE_SCAN».

Betrachten wir nun die Suche nach dem Kurznamen. Auf der Spalte Kurzname existiert ebenfalls ein Index. Einen Index kann man sich wie ein Wörterbuch vorstellen. Sucht man in einem Wörterbuch z.B. nach dem Namen «RAYMOND», so findet man diesen schnell, da die Wörter alphabetisch geordnet sind. Weniger hilfreich ist das Wörterbuch, wenn man nur Teile des gesuchten Wortes kennt, wie zum Beispiel bei der Suche nach «R*MOND». Nahezu keine Hilfe bietet das Wörterbuch mehr, wenn der Anfangsteil des gesuchten Wortes fehlt, zum Beispiel bei «*MON*». In diesem Fall ist man gezwungen das gesamte Wörterbuch zu lesen und für jedes Wort zu entscheiden ob der gesuchte Wortteil «MON» enthalten ist.
Der Datenbank geht es genauso! Im letzten Fall spricht man im Fachjargon unter anderem von einem «FULL TABLE SCAN». Bei einer Tabellengrösse von einigen tausend Zeilen ist ein «FULL TABLE SCAN» für die Datenbank kein Problem und oftmals sogar die beste Wahl. So verwenden wir einen «FULL TABLE SCAN» beispielsweise bei der Stierensuche. Bei dieser wird ab einer periodisch aktualisierten Tabelle mit rund 43’000 Tieren gesucht.
Bei der Tiersuche über die gesamte Tabelle ANIMAL dauert ein «FULL TABLE SCAN» aber mehrere Minuten. Das dauert zu lange und ist somit keine praktikable Lösung.

Textsuche ist eine weitverbreitete Anforderung und ORACLE bietet mit ORACLE TEXT auch eine Lösung. Ich möchte betonen, dass ORACLE TEXT ein sehr umfassendes Produkt ist und nicht primär für die Volltextsuche innerhalb eines Wortes entwickelt wurde. Eine Kernanwendung von ORACLE TEXT ist es, aus einer Fülle von Dokumenten (typischerweise Formate wie PDF oder Word) diejenigen Dokumente zu suchen, welche die gesuchten Worte enthalten. Damit ähnelt die Funktionsweise von ORACLE TEXT sehr stark einer Suchmaschine wie Google. Durch die facettenreichen Konfigurationsmöglichkeiten der ORACLE TEXT Indices konnten wir aber einen Index erstellen, welcher bei der Volltexsuche eines Tiernamens hilfreich ist.
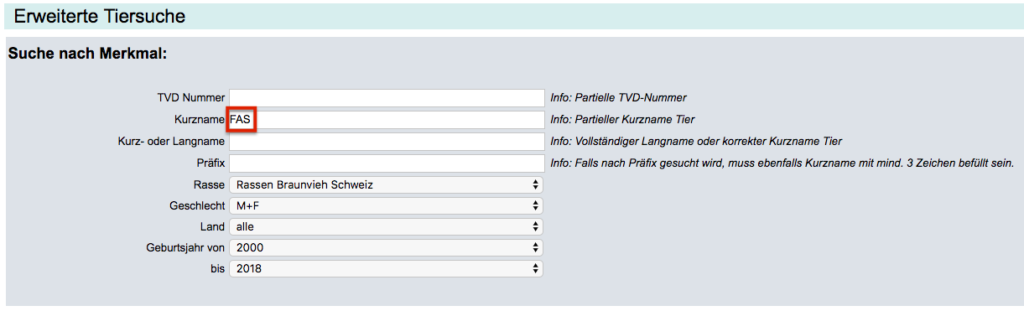
Beispiel: Wir können innerhalb von weniger als 1 Sekunde aus 18.5 Millionen Records diejenigen filtern (n ~ 4’000), welche «*FAS*» im Namen haben. Dabei finden wir den Namen «FASAN» ebenso wie den Namen «LORFASTA». Für die Darstellung der Suchresultate auf der Weboberfläche mit weiteren Suchfiltern, wie der gewünschten Rassen und dem gewünschten Geburtsdatum, benötigt das System insgesamt etwa 5 Sekunden.
Um die Volltextsuche der TVD-Nummer zu ermöglichen haben wir analog ein ORACLE TEXT Index auf der TVD-Nummer erstellt. Gerade die Indexierung einer 12-stelligen Zahl als Text ist von der Kernanwendung von ORACLE TEXT weit entfernt. Der aktive Wortschatz in der deutschen Sprache zählt 12’000 bis 16’000 Wörter. Das ist verglichen mit den Snippets einer 12-stelligen Zahl bei 18.5 Millionen Einträgen sehr klein. Dies zeigt sich auch in der immensen Grösse des Index von 7 Gigabytes. Der Index ist damit grösser als die gesamte Tabelle ANIMAL.
Anders als die konventionellen Indices von ORACLE müssen wir die ORACLE TEXT Indices periodisch synchronisieren, damit sie die aktuellen Daten abbilden. Im vorgestellten Fall läuft die Synchronisation täglich.

Die Arbeit mit ORACLE TEXT war für mich als Entwickler eine spannende Herausforderung. Die gewonnenen Erkenntnisse bringen unser ganzes Team weiter und bringen auch an anderer Stelle enormen Nutzen. Mit der überarbeiteten Suche konnten wir unseren Mandanten und schlussendlich deren Endkunden ein tolles Endprodukt liefern. Benutzerfreundlichkeit und das schnelle und zielgerichtete Suchen nach Tieren ist damit nun möglich.